Nanodegree key: nd009t
Version: 5.0.0
Locale: en-us
This course concentrates on training the learner to become a machine learning engineer and apply predictive models to massive data sets in fields like education, finance, healthcare, or robotics.
Content
Part 01 : Welcome to the Nanodegree program
-
Module 01: Welcome to the Nanodegree program
-
Lesson 01: Welcome to the Nanodegree program
Welcome to Nanodegree program!
-
Lesson 02: Get Help with Your Account
What to do if you have questions about your account or general questions about the program.
-
Part 02 : Software Engineering Fundamentals
-
Module 01: Software Engineering
-
Lesson 01: Introduction to Software Engineering
Welcome to Software Engineering for Data Scientists! Learn about the course and meet your instructors.
-
Lesson 02: Software Engineering Practices Pt I
Learn software engineering practices and how they apply in data science. Part one covers clean and modular code, code efficiency, refactoring, documentation, and version control.
- Concept 01: Introduction
- Concept 02: Clean and Modular Code
- Concept 03: Refactoring Code
- Concept 04: Writing Clean Code
- Concept 05: Quiz: Clean Code
- Concept 06: Writing Modular Code
- Concept 07: Quiz: Refactoring - Wine Quality
- Concept 08: Solution: Refactoring - Wine Quality
- Concept 09: Efficient Code
- Concept 10: Optimizing - Common Books
- Concept 11: Quiz: Optimizing - Common Books
- Concept 12: Solution: Optimizing - Common Books
- Concept 13: Quiz: Optimizing - Holiday Gifts
- Concept 14: Solution: Optimizing - Holiday Gifts
- Concept 15: Documentation
- Concept 16: In-line Comments
- Concept 17: Docstrings
- Concept 18: Project Documentation
- Concept 19: Documentation
- Concept 20: Version Control in Data Science
- Concept 21: Scenario #1
- Concept 22: Scenario #2
- Concept 23: Scenario #3
- Concept 24: Model Versioning
- Concept 25: Conclusion
-
Lesson 03: Software Engineering Practices Pt II
Learn software engineering practices and how they apply in data science. Part two covers testing code, logging, and conducting code reviews.
- Concept 01: Introduction
- Concept 02: Testing
- Concept 03: Testing and Data Science
- Concept 04: Unit Tests
- Concept 05: Unit Testing Tools
- Concept 06: Quiz: Unit Tests
- Concept 07: Test Driven Development and Data Science
- Concept 08: Logging
- Concept 09: Log Messages
- Concept 10: Logging
- Concept 11: Code Review
- Concept 12: Questions to Ask Yourself When Conducting a Code Review
- Concept 13: Tips for Conducting a Code Review
- Concept 14: Conclusion
-
Lesson 04: Introduction to Object-Oriented Programming
Learn the basics of object-oriented programming so that you can build your own Python package.
- Concept 01: Introduction
- Concept 02: Procedural vs. Object-Oriented Programming
- Concept 03: Class, Object, Method and Attribute
- Concept 04: OOP Syntax
- Concept 05: Exercise: OOP Syntax Practice - Part 1
- Concept 06: A Couple of Notes about OOP
- Concept 07: Exercise: OOP Syntax Practice - Part 2
- Concept 08: Commenting Object-Oriented Code
- Concept 09: A Gaussian Class
- Concept 10: How the Gaussian Class Works
- Concept 11: Exercise: Code the Gaussian Class
- Concept 12: Magic Methods
- Concept 13: Exercise: Code Magic Methods
- Concept 14: Inheritance
- Concept 15: Exercise: Inheritance with Clothing
- Concept 16: Inheritance: Probability Distribution
- Concept 17: Demo: Inheritance Probability Distributions
- Concept 18: Advanced OOP Topics
- Concept 19: Organizing into Modules
- Concept 20: Demo: Modularized Code
- Concept 21: Making a Package
- Concept 22: Virtual Environments
- Concept 23: Exercise: Making a Package and Pip Installing
- Concept 24: Binomial Class
- Concept 25: Exercise: Binomial Class
- Concept 26: Scikit-learn Source Code
- Concept 27: Putting Code on PyPi
- Concept 28: Exercise: Upload to PyPi
- Concept 29: Lesson Summary
-
Lesson 05: Portfolio Exercise: Upload a Package to PyPi
Create your own Python package and upload your package to PyPi.
-
Part 03 : Machine Learning in Production
-
Module 01: Deployment
-
Lesson 01: Introduction to Deployment
This lesson will familiarizing the student with cloud and deployment terminology along with demonstrating how deployment fits within the machine learning workflow.
- Concept 01: Welcome!
- Concept 02: What's Ahead?
- Concept 03: Problem Introduction
- Concept 04: Machine Learning Workflow
- Concept 05: Machine Learning Workflow
- Concept 06: What is Cloud Computing & Why Would We Use It?
- Concept 07: Why Cloud Computing?
- Concept 08: Machine Learning Applications
- Concept 09: Machine Learning Applications
- Concept 10: Paths to Deployment
- Concept 11: Paths to Deployment
- Concept 12: Production Environments
- Concept 13: Production Environments
- Concept 14: Endpoints & REST APIs
- Concept 15: Endpoints & REST APIs
- Concept 16: Containers
- Concept 17: Containers
- Concept 18: Containers - Straight From the Experts
- Concept 19: Characteristics of Modeling & Deployment
- Concept 20: Characteristics of Modeling & Deployment
- Concept 21: Comparing Cloud Providers
- Concept 22: Comparing Cloud Providers
- Concept 23: Closing Statements
- Concept 24: Summary
- Concept 25: [Optional] Cloud Computing Defined
- Concept 26: [Optional] Cloud Computing Explained
-
Lesson 02: Building a Model using SageMaker
Learn how to use Amazon’s SageMaker service to predict Boston housing prices using SageMaker’s built-in XGBoost algorithm.
- Concept 01: Introduction to Amazon SageMaker
- Concept 02: AWS Setup Instructions for Regular account
- Concept 03: AWS SageMaker
- Concept 04: SageMaker Instance Utilization Limits
- Concept 05: Setting up a Notebook Instance
- Concept 06: Cloning the Deployment Notebooks
- Concept 07: Is Everything Set Up?
- Concept 08: Boston Housing Example - Getting the Data Ready
- Concept 09: Boston Housing Example - Training the Model
- Concept 10: Boston Housing Example - Testing the Model
- Concept 11: Mini-Project: Building Your First Model
- Concept 12: Mini-Project: Solution
- Concept 13: Boston Housing In-Depth - Data Preparation
- Concept 14: Boston Housing In-Depth - Creating a Training Job
- Concept 15: Boston Housing In-Depth - Building a Model
- Concept 16: Boston Housing In-Depth - Creating a Batch Transform Job
- Concept 17: Summary
-
Lesson 03: Deploying and Using a Model
In this lesson students will learn how to deploy a model using SageMaker and how to make use of their deployed model with a simple web application.
- Concept 01: Deploying a Model in SageMaker
- Concept 02: Boston Housing Example - Deploying the Model
- Concept 03: Boston Housing In-Depth - Deploying the Model
- Concept 04: Deploying and Using a Sentiment Analysis Model
- Concept 05: Text Processing, Bag of Words
- Concept 06: Building and Deploying the Model
- Concept 07: How to Use a Deployed Model
- Concept 08: Creating and Using an Endpoint
- Concept 09: Building a Lambda Function
- Concept 10: Building an API
- Concept 11: Using the Final Web Application
- Concept 12: Summary
-
Lesson 04: Hyperparameter Tuning
In this lesson students will see how to use SageMaker’s automatic hyperparameter tuning tools on the Boston housing prices model from lesson 2 and with a sentiment analysis model.
- Concept 01: Hyperparameter Tuning
- Concept 02: Introduction to Hyperparameter Tuning
- Concept 03: Boston Housing Example - Tuning the Model
- Concept 04: Mini-Project: Tuning the Sentiment Analysis Model
- Concept 05: Mini-Project: Solution - Tuning the Model
- Concept 06: Mini-Project: Solution - Fixing the Error and Testing
- Concept 07: Boston Housing In-Depth - Creating a Tuning Job
- Concept 08: Boston Housing In-Depth - Monitoring the Tuning Job
- Concept 09: Boston Housing In-Depth - Building and Testing the Model
- Concept 10: Summary
-
Lesson 05: Updating a Model
In this lesson students will learn how to update their model to account for changes in the underlying data used to train their model.
- Concept 01: Updating a Model
- Concept 02: Building a Sentiment Analysis Model (XGBoost)
- Concept 03: Building a Sentiment Analysis Model (Linear Learner)
- Concept 04: Combining the Models
- Concept 05: Mini-Project: Updating a Sentiment Analysis Model
- Concept 06: Loading and Testing the New Data
- Concept 07: Exploring the New Data
- Concept 08: Building a New Model
- Concept 09: SageMaker Retrospective
- Concept 10: Cleaning Up Your AWS Account
- Concept 11: SageMaker Tips and Tricks
-
-
Module 02: Project: Deploying a Sentiment Analysis Model
Part 04 : Machine Learning, Case Studies
-
Module 01: Machine Learning, Case Studies
-
Lesson 01: Population Segmentation
Train and deploy unsupervised models (PCA and k-means clustering) to group US counties by similarities and differences. Visualize the trained model attributes and interpret the results.
- Concept 01: Introducing Cezanne & Dan
- Concept 02: Interview Segment: What is SageMaker and Why Learn It?
- Concept 03: Course Outline, Case Studies
- Concept 04: Unsupervised v Supervised Learning
- Concept 05: Model Design
- Concept 06: Population Segmentation
- Concept 07: K-means, Overview
- Concept 08: Creating a Notebook Instance
- Concept 09: Create a SageMaker Notebook Instance
- Concept 10: Pre-Notebook: Population Segmentation
- Concept 11: Exercise: Data Loading & Processing
- Concept 12: Solution: Data Pre-Processing
- Concept 13: Exercise: Normalization
- Concept 14: Solution: Normalization
- Concept 15: PCA, Overview
- Concept 16: PCA Estimator & Training
- Concept 17: Exercise: PCA Model Attributes & Variance
- Concept 18: Solution: Variance
- Concept 19: Component Makeup
- Concept 20: Exercise: PCA Deployment & Data Transformation
- Concept 21: Solution: Creating Transformed Data
- Concept 22: Exercise: K-means Estimator & Selecting K
- Concept 23: Exercise: K-means Predictions (clusters)
- Concept 24: Solution: K-means Predictor
- Concept 25: Exercise: Get the Model Attributes
- Concept 26: Solution: Model Attributes
- Concept 27: Clean Up: All Resources
- Concept 28: AWS Workflow & Summary
-
Lesson 02: Payment Fraud Detection
Train a linear model to do credit card fraud detection. Improve the model by accounting for class imbalance in the training data and tuning for a specific performance metric.
- Concept 01: Fraud Detection
- Concept 02: Pre-Notebook: Payment Fraud Detection
- Concept 03: Exercise: Payment Transaction Data
- Concept 04: Solution: Data Distribution & Splitting
- Concept 05: LinearLearner & Class Imbalance
- Concept 06: Exercise: Define a LinearLearner
- Concept 07: Solution: Default LinearLearner
- Concept 08: Exercise: Format Data & Train the LinearLearner
- Concept 09: Solution: Training Job
- Concept 10: Precision & Recall, Overview
- Concept 11: Exercise: Deploy Estimator
- Concept 12: Solution: Deployment & Evaluation
- Concept 13: Model Improvements
- Concept 14: Improvement, Model Tuning
- Concept 15: Exercise: Improvement, Class Imbalance
- Concept 16: Solution: Accounting for Class Imbalance
- Concept 17: Exercise: Define a Model w/ Specifications
- Concept 18: One Solution: Tuned and Balanced LinearLearner
- Concept 19: Summary and Improvements
-
Lesson 03: Interview Segment: SageMaker as a Tool & the Future of ML
If you're interested in how SageMaker has developed to serve businesses and learners, take a look at this short interview segment with Dan Mbanga.
-
Lesson 04: Deploying Custom Models
Design and train a custom PyTorch classifier by writing a training script. This is an especially useful skill for tasks that cannot be easily solved by built-in algorithms.
- Concept 01: Pre-Notebook: Custom Models & Moon Data
- Concept 02: Moon Data & Custom Models
- Concept 03: Upload Data to S3
- Concept 04: Exercise: Custom PyTorch Classifier
- Concept 05: Solution: Simple Neural Network
- Concept 06: Exercise: Training Script
- Concept 07: Solution: Complete Training Script
- Concept 08: Custom SKLearn Model
- Concept 09: PyTorch Estimator
- Concept 10: Exercise: Create a PyTorchModel & Endpoint
- Concept 11: Solution: PyTorchModel & Evaluation
- Concept 12: Clean Up: All Resources
- Concept 13: Summary of Skills
-
Lesson 05: Time-Series Forecasting
Learn how to format time series data into context (input) and prediction (output) data, and train the built-in algorithm, DeepAR; this uses an RNN to find recurring patterns in time series data.
- Concept 01: Time-Series Forecasting
- Concept 02: Forecasting Energy Consumption, Notebook
- Concept 03: Pre-Notebook: Time-Series Forecasting
- Concept 04: Processing Energy Data
- Concept 05: Exercise: Creating Time Series
- Concept 06: Solution: Split Data
- Concept 07: Exercise: Convert to JSON
- Concept 08: Solution: Formatting JSON Lines & DeepAR Estimator
- Concept 09: Exercise: DeepAR Estimator
- Concept 10: Solution: Complete Estimator & Hyperparameters
- Concept 11: Making Predictions
- Concept 12: Exercise: Predicting the Future
- Concept 13: Solution: Predicting Future Data
- Concept 14: Clean Up: All Resources
-
-
Module 02: Project: Plagiarism Detector
-
Module 03: Career Support: GitHub Review
-
Lesson 01: Get Quick Feedback on Your GitHub Profile
Other professionals are collaborating on GitHub and growing their network. Submit your profile to ensure your profile is on par with leaders in your field.
- Concept 01: Prove Your Skills With GitHub
- Concept 02: Introduction
- Concept 03: GitHub profile important items
- Concept 04: Good GitHub repository
- Concept 05: Interview with Art - Part 1
- Concept 06: Identify fixes for example “bad” profile
- Concept 07: Quick Fixes #1
- Concept 08: Quick Fixes #2
- Concept 09: Writing READMEs with Walter
- Concept 10: Interview with Art - Part 2
- Concept 11: Commit messages best practices
- Concept 12: Reflect on your commit messages
- Concept 13: Participating in open source projects
- Concept 14: Interview with Art - Part 3
- Concept 15: Participating in open source projects 2
- Concept 16: Starring interesting repositories
- Concept 17: Next Steps
-
-
Module 04: Career Support: LinkedIn Review
-
Lesson 01: Take 30 Min to Improve your LinkedIn
Find your next job or connect with industry peers on LinkedIn. Ensure your profile attracts relevant leads that will grow your professional network.
- Concept 01: Get Opportunities with LinkedIn
- Concept 02: Use Your Story to Stand Out
- Concept 03: Why Use an Elevator Pitch
- Concept 04: Create Your Elevator Pitch
- Concept 05: Use Your Elevator Pitch on LinkedIn
- Concept 06: Create Your Profile With SEO In Mind
- Concept 07: Profile Essentials
- Concept 08: Work Experiences & Accomplishments
- Concept 09: Build and Strengthen Your Network
- Concept 10: Reaching Out on LinkedIn
- Concept 11: Boost Your Visibility
- Concept 12: Up Next
-
Part 05 : Build Your Own Machine Learning Portfolio Project
-
Module 01: Capstone Project
-
Lesson 01: Machine Learning Engineer Capstone Project
Put your Machine Learning Engineer skills to the test by solving a real-world problem using all that you have learned throughout the program.
- Concept 01: Project Overview
- Concept 02: Software & Data Requirements
- Concept 03: Possible Projects
- Concept 04: Bertelsmann/Arvato Project Overview
- Concept 05: Arvato: Terms and Conditions
- Concept 06: Bertelsmann/Arvato Project Workspace
- Concept 07: Starbucks Project Overview
- Concept 08: Starbucks Project Workspace
- Concept 09: CNN Project: Dog Breed Classifier
- Concept 10: Dog Project Workspace
- Concept 11: Selecting One Project
-
Part 06 : Congratulations!
-
Module 01: Congratulations!
-
Lesson 01: Congratulations!
You've completed the Machine Learning Engineer Nanodegree program!
-
Part 07 (Elective): Additional Materials: NLP Fundamentals
-
Module 01: Introduction to NLP
-
Lesson 01: Introduction to NLP
Learn how text is represented in natural language models; transform text using methods like Bag-of-Words, TF-IDF, Word2Vec and GloVE.
- Concept 01: NLP and Pipelines
- Concept 02: How NLP Pipelines Work
- Concept 03: Text Processing
- Concept 04: Feature Extraction
- Concept 05: Bag of Words
- Concept 06: TF-IDF
- Concept 07: One-Hot Encoding
- Concept 08: Word Embeddings
- Concept 09: Word2Vec
- Concept 10: GloVe
- Concept 11: Embeddings for Deep Learning
- Concept 12: Modeling
-
-
Module 02: Implementing RNNs
-
Lesson 01: Implementation of RNN & LSTM
Learn how to represent memory in code. Then define and train RNNs in PyTorch and apply them to tasks that involve sequential data.
- Concept 01: Implementing RNNs
- Concept 02: Time-Series Prediction
- Concept 03: Training & Memory
- Concept 04: Character-wise RNNs
- Concept 05: Sequence Batching
- Concept 06: Pre-Notebook: Character-Level RNN
- Concept 07: Notebook: Character-Level RNN
- Concept 08: Implementing a Char-RNN
- Concept 09: Batching Data, Solution
- Concept 10: Defining the Model
- Concept 11: Char-RNN, Solution
- Concept 12: Making Predictions
-
Lesson 02: Sentiment Prediction RNN
Implement a sentiment prediction RNN for predicting whether a movie review is positive or negative!
- Concept 01: Sentiment RNN, Introduction
- Concept 02: Pre-Notebook: Sentiment RNN
- Concept 03: Notebook: Sentiment RNN
- Concept 04: Data Pre-Processing
- Concept 05: Encoding Words, Solution
- Concept 06: Getting Rid of Zero-Length
- Concept 07: Cleaning & Padding Data
- Concept 08: Padded Features, Solution
- Concept 09: TensorDataset & Batching Data
- Concept 10: Defining the Model
- Concept 11: Complete Sentiment RNN
- Concept 12: Training the Model
- Concept 13: Testing
- Concept 14: Inference, Solution
-
Part 08 (Elective): Additional Materials: Convolutional Neural Networks
-
Module 01: Convolutional Neural Networks
-
Lesson 01: Convolutional Neural Networks
Convolutional Neural Networks allow for spatial pattern recognition. Alexis and Cezanne go over how they help us dramatically improve performance in image classification.
- Concept 01: Introducing Alexis
- Concept 02: Applications of CNNs
- Concept 03: Lesson Outline
- Concept 04: MNIST Dataset
- Concept 05: How Computers Interpret Images
- Concept 06: MLP Structure & Class Scores
- Concept 07: Do Your Research
- Concept 08: Loss & Optimization
- Concept 09: Defining a Network in PyTorch
- Concept 10: Training the Network
- Concept 11: Pre-Notebook: MLP Classification, Exercise
- Concept 12: Notebook: MLP Classification, MNIST
- Concept 13: One Solution
- Concept 14: Model Validation
- Concept 15: Validation Loss
- Concept 16: Image Classification Steps
- Concept 17: MLPs vs CNNs
- Concept 18: Local Connectivity
- Concept 19: Filters and the Convolutional Layer
- Concept 20: Filters & Edges
- Concept 21: Frequency in Images
- Concept 22: High-pass Filters
- Concept 23: Quiz: Kernels
- Concept 24: OpenCV & Creating Custom Filters
- Concept 25: Notebook: Finding Edges
- Concept 26: Convolutional Layer
- Concept 27: Convolutional Layers (Part 2)
- Concept 28: Stride and Padding
- Concept 29: Pooling Layers
- Concept 30: Notebook: Layer Visualization
- Concept 31: Capsule Networks
- Concept 32: Increasing Depth
- Concept 33: CNNs for Image Classification
- Concept 34: Convolutional Layers in PyTorch
- Concept 35: Feature Vector
- Concept 36: Pre-Notebook: CNN Classification
- Concept 37: Notebook: CNNs for CIFAR Image Classification
- Concept 38: CIFAR Classification Example
- Concept 39: CNNs in PyTorch
- Concept 40: Image Augmentation
- Concept 41: Augmentation Using Transformations
- Concept 42: Groundbreaking CNN Architectures
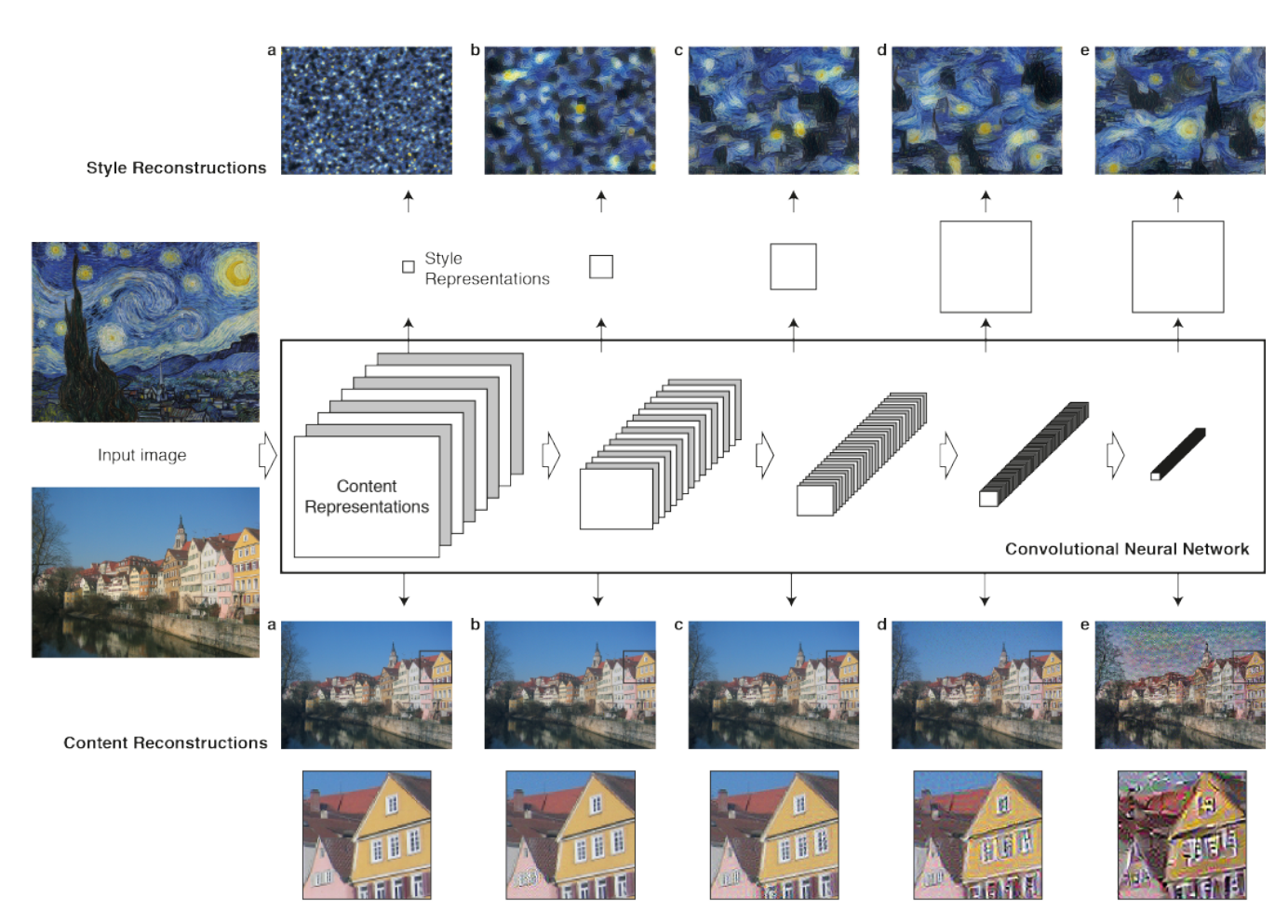
- Concept 43: Visualizing CNNs (Part 1)
- Concept 44: Visualizing CNNs (Part 2)
- Concept 45: Summary of CNNs
- Concept 46: Introduction to GPU Workspaces
- Concept 47: Workspace Playground
- Concept 48: GPU Workspace Playground
-
Lesson 02: GPU Workspaces Demo
See a demonstration of GPU workspaces in the Udacity classroom.
-
Lesson 03: Cloud Computing
Take advantage of Amazon's GPUs to train your neural network faster. In this lesson, you'll setup an instance on AWS and train a neural network on a GPU.
-
Lesson 04: Transfer Learning
Learn how to apply a pre-trained network to a new problem with transfer learning.
-
Lesson 05: Weight Initialization
In this lesson, you'll learn how to find good initial weights for a neural network. Having good initial weights can place the neural network closer to the optimal solution.
- Concept 01: Weight Initialization
- Concept 02: Constant Weights
- Concept 03: Random Uniform
- Concept 04: General Rule
- Concept 05: Normal Distribution
- Concept 06: Pre-Notebook: Weight Initialization, Normal Distribution
- Concept 07: Notebook: Normal & No Initialization
- Concept 08: Solution and Default Initialization
- Concept 09: Additional Material
-
Lesson 06: Autoencoders
Autoencoders are neural networks used for data compression, image de-noising, and dimensionality reduction. Here, you'll build autoencoders using PyTorch.
- Concept 01: Autoencoders
- Concept 02: A Linear Autoencoder
- Concept 03: Pre-Notebook: Linear Autoencoder
- Concept 04: Notebook: Linear Autoencoder
- Concept 05: Defining & Training an Autoencoder
- Concept 06: A Simple Solution
- Concept 07: Learnable Upsampling
- Concept 08: Transpose Convolutions
- Concept 09: Convolutional Autoencoder
- Concept 10: Pre-Notebook: Convolutional Autoencoder
- Concept 11: Notebook: Convolutional Autoencoder
- Concept 12: Convolutional Solution
- Concept 13: Upsampling & Denoising
- Concept 14: De-noising
- Concept 15: Pre-Notebook: De-noising Autoencoder
- Concept 16: Notebook: De-noising Autoencoder
-
Part 09 (Elective): Additional Materials: Web Deployment with Flask
-
Module 01: Web Deployment with Flask
-
Lesson 01: Web Development
Develop a data dashboard using Flask, Bootstrap, Plotly and Pandas.
- Concept 01: Introduction
- Concept 02: Lesson Overview
- Concept 03: The Web
- Concept 04: Components of a Web App
- Concept 05: The Front-End
- Concept 06: HTML
- Concept 07: Exercise: HTML
- Concept 08: Div and Span
- Concept 09: IDs and Classes
- Concept 10: Exercise: HTML Div, Span, IDs, Classes
- Concept 11: CSS
- Concept 12: Exercise: CSS
- Concept 13: Bootstrap Library
- Concept 14: Exercise: Bootstrap
- Concept 15: JavaScript
- Concept 16: Exercise: JavaScript
- Concept 17: Plotly
- Concept 18: Exercise: Plotly
- Concept 19: The Backend
- Concept 20: Flask
- Concept 21: Exercise: Flask
- Concept 22: Flask + Pandas
- Concept 23: Example: Flask + Pandas
- Concept 24: Flask+Plotly+Pandas Part 1
- Concept 25: Flask+Plotly+Pandas Part 2
- Concept 26: Flask+Plotly+Pandas Part 3
- Concept 27: Flask+Plotly+Pandas Part 4
- Concept 28: Example: Flask + Plotly + Pandas
- Concept 29: Exercise: Flask + Plotly + Pandas
- Concept 30: Deployment
- Concept 31: Exercise: Deployment
- Concept 32: Lesson Summary
-
Lesson 02: Portfolio Exercise: Deploy a Data Dashboard
Customize the data dashboard from the previous lesson to make it your own. Upload the dashboard to the web.
- Concept 01: Introduction
- Concept 02: Workspace Portfolio Exercise
- Concept 03: Troubleshooting Possible Errors
- Concept 04: Congratulations
- Concept 05: APIs [advanced version]
- Concept 06: World Bank API [advanced version]
- Concept 07: Python and APIs [advanced version]
- Concept 08: World Bank Data Dashboard [advanced version]
-
Part 10 (Elective): Additional Materials: Version Control
Here is a link to our free course on Version Control.
-
Module 01: Version Control
-
Lesson 01: What is Version Control?
Version control is an incredibly important part of a professional programmer's life. In this lesson, you'll learn about the benefits of version control and install the version control tool Git!
-
Lesson 02: Create a Git Repo
Now that you've learned the benefits of Version Control and gotten Git installed, it's time you learn how to create a repository.
-
Lesson 03: Review A Repo's History
Knowing how to review an existing Git repository's history of commits is extremely important. You'll learn how to do just that in this lesson.
-
Lesson 04: Add Commits to A Repo
A repository is nothing without commits. In this lesson, you'll learn how to make commits, write descriptive commit messages, and verify the changes you're about to save to the repository.
-
Lesson 05: Tagging, Branching, and Merging
Being able to work on your project in isolation from other changes will multiply your productivity. You'll learn how to do this isolated development with Git's branches.
-
Lesson 06: Undoing Changes
Help! Disaster has struck! You don't have to worry, though, because your project is tracked in version control! You'll learn how to undo and modify changes that have been saved to the repository.
-